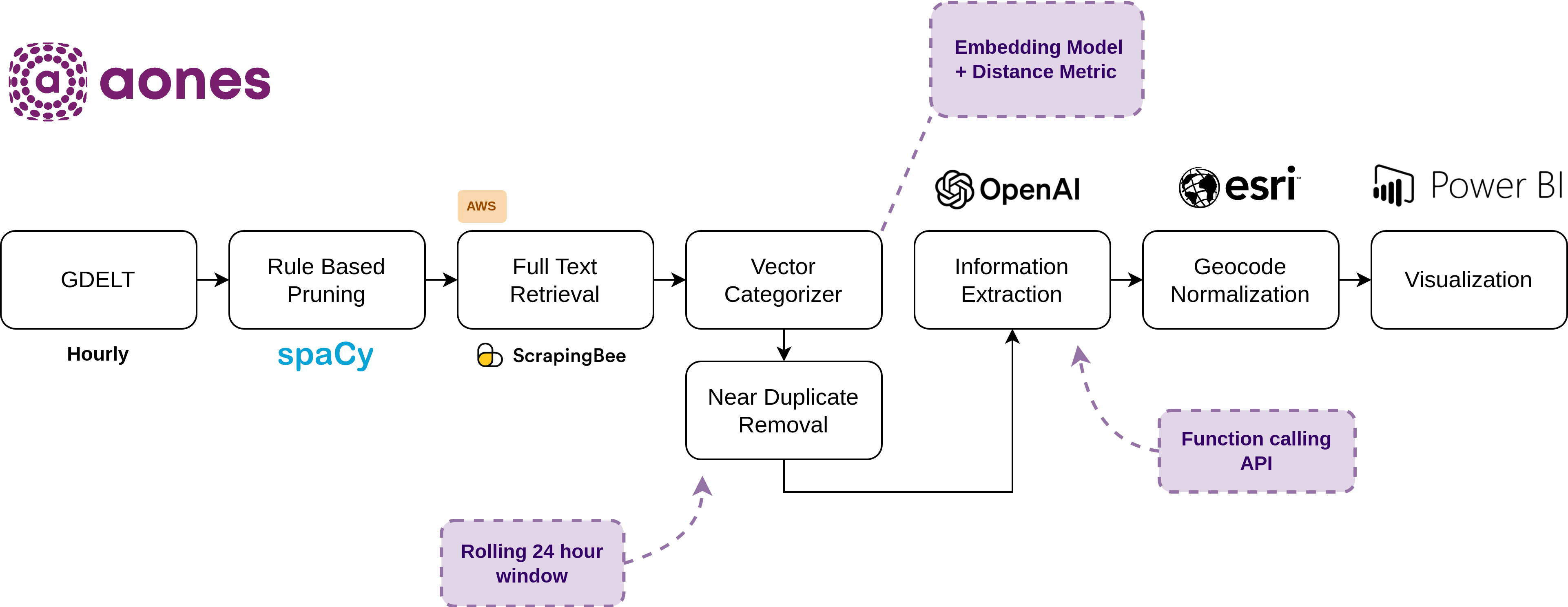
Data Pipeline
This page summarizes how the data for AONES is sourced, filtered and extracted. The steps are summarized in the figure below, with sections of the page for each major component.
The news media reports on a wide range of articles related to opioids. Some of these articles are entirely unrelated to AONES, for example articles about: the regulated use of opioids for pain, pharmaceutical companies making opioids, or the portrayal of opioids in the arts. However, even within the topic of the unregulated drug supply, there are a wide range of articles including those on:
- warnings and alerts on spikes in overdoses and other negative outcomes,
- reports and studies (governmental, academic or other) on epidemiological trends in opioid use,
- policy and harm reduction programs,
- crime (anything from possession charges to larger drug busts (drug confiscations), or charges related to fatal overdoses), and
- the justice system (i.e., trial proceedings and outcomes of charges related to opioid crimes).
AONES aims to provide near real-time information on events within the unregulated drug supply and so the scope needs to be limited to only articles most likely to contain up-to-date information on this. To determine which types of articles were most relevant, both the Locally Driven Collaborative Project’s (LDCP) Knowledge Advisory Group, as well as ODPRN’s LEAG Group were consulted. The types of information about the unregulated drug supply that would likely be included in the articles was considered (e.g., what kinds of drugs are circulating, what contaminants are being introduced to the supply, what outcomes are occurring). Two main categories of articles in scope were identified:
- Drug alerts/warnings (called alert): these are articles related to sudden spikes in overdoses, emergency department visits and/or other negative outcomes. They may or may not include the names of specific drugs, their appearance, contaminants within the drugs, or specific outcomes. They are often provided by health or community organizations or the police for a specific region.
- Drug confiscations (also called crime): these are articles that name specific drugs seized by the police. They may or may not include descriptions of the form and/or appearance of the drugs, or the quantity confiscated. While the focus of this category is larger drug busts, it can include individual possession charges.
The main data source used by AONES to capture news media is the Global Database of Events, Language, and Tone (GDELT). GDELT collects and monitors print, broadcast and web-based news media from around the world. It makes both unprocessed lists of articles and their metadata available for free. AONES uses two of these sources:
- GDELT Article List (GAL) is a list of every collected by GDELT. It only includes the basic set of standardized metadata, for example the date, title, url, language and in some cases a 1-2 sentence description. This dataset is used by AONES as it is the most complete record of articles, but the limited contextual information (title and maybe a description) means it may not be possible to determine if an article is opioid-related.
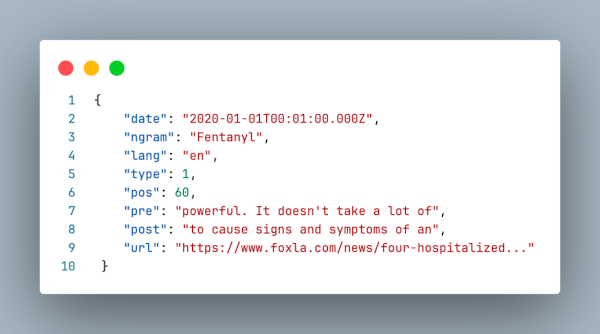
- Web News NGrams 3.0 (NGRAM) is a dataset that splits articles into individual words (called a unigram). A record is created for each unigram in the full text of the article, which also contains the basic metadata (date, language, url), the location of the unigram in the text, and some of the preceding and following words. This dataset is used by AONES as it provides sections of the full text of the articles, providing more information for the system to use to decide if an article is opioid-related. An example of an NGRAM record is provided below for context.
The cleaned hourly datasets from GDELT contain all English-language articles, generally thousands of records. To filter these datasets to only opioid-related articles, an efficient and low-resource intensity method is required and so AONES uses a rule-based filtering method. The primary goal of this stage is to decrease the volume for the more resource-intensity stages in the data pipeline, not to identify articles that are specifically within the scope of AONES (this happens later). Generally, there are a few hundred articles remaining after the rule-based filtering step.
The rule-based method uses keyword pattern matching implemented using spaCy. spaCy is an open-source python library for natural language processing (NLP). It is used by AONES to tokenize the available text fields (the title and description from GAL, or the large text fragment from NGRAM). Tokenizing is when the text is broken into individual words and punctuation (similar in theory to the unigrams used by GDELT). These individual tokens are then compared to a set of opioid keyword patterns, using a process similar to regular expressions. Patterns can be individual keywords, e.g., “heroin”, or components of keywords that account for variations in spellings/terms, e.g., opioid/opiate/opium can be captured by a pattern that requires the “op” and provides alternate endings to the word. Patterns can also be defined by multiple words in a specific order, or combinations of words.
A wide range of opioid-related terms are included in the patterns, including terms related to other unregulated drugs. The list of terms included is monitored and updated as necessary. The terms are grouped into the follow categories:
- Opioids: an extensive list of names of specific opioid drugs, e.g., morphine, heroin, fentanyl, carfentanil, and various nitazenes.
- Opioid agonists: e.g., suboxone, methadone, buprenorphine.
- Opioid antagonists: e.g., naloxone, Narcan.
- Benzodiazepines: e.g., an extensive list of names of specific benzodiazepines, e.g., diazepam, bromazolam, flualprazolam.
- Other substances: this includes both specific drug names, e.g., cocaine, ecstasy, crystal meth, and general terms, e.g., illicit drugs, white flaky substances.
- Street drug terms: this includes known street names of various drugs, e.g., oxy, m30, percs, dillies. This is likely not an exhaustive list.
- Drug toxicity phrases: e.g., overdoses, drug poisoning or drug calls.
- Drug supply phrases: e.g., contamination AND drug supply, drug AND traffic.
After both the GAL and NGRAM datasets are filtered to only articles matching at least one of the patterns, the two datasets are then merged into a single complete list of unique urls.
The full text of all opioid-related articles is retrieved using a service called ScrapingBee. The url is sent to Scraping Bee and the raw HTML code of the website is returned. It may not be possible to receive the full text of all articles, including those from JavaScript-heavy websites or with significant paywalls. The open-source python package Trafilatura is then used to extract only the date, title and main body of the text from the raw HTML returned by ScrapingBee.
Once the full text of the article is retrieved, an additional, more complex, filtering step is done. The goal of this step is to limit the full list of opioid-related articles to only those in scope of AONES, i.e., a primary focus on alerts and drug confiscations. Furthermore, this step categorizes the in-scope articles into one of the alert, crime and other classifications. This stage uses a method called vector categorization, which is a type of similarity search. To power this search, hundreds of articles were manually labelled as one of the three categories. Only good examples were included in this dataset and it is continually updated.
For each new article a numerical representation of the text is created using a neural network. To do this, an open-source embedding model named Nomic is used. The created numerical representation (the vector) is compared to vectors for the articles in the manually labelled dataset. A nearest-neighbours-style search is performed to find the distance from the current article to the closest article in labelled dataset. This distance is then compared to a threshold, with only articles meeting the threshold kept. Kept articles are then given a category based on the labelled category of the “nearest neighbour”. A simplified visual depiction of this nearest neighbours logic is provided below. The final dataset contains the basic metadata (date, url, title), the full text and the classification.

After categorization, preliminary efforts are undertaken to minimize the duplication of articles in the dataset. There are a few types of duplication of articles:
- The same article posted on multiple related news organizations’ sites. Given the large corporate landscape of news media in North America, especially for smaller city and town newspapers, the same article can appear on multiple sites (i.e., with multiple unique urls). These articles are typically identical but may have small variations and are typically posted within a few hours of each other.
- Articles originating from national or international news agencies (e.g., Reuters or the Associated Press). When posted on the final news organizations website, these articles can be very similar to the original report from the news agency, resulting in nearly identical articles on multiple websites, but may also be significantly rewritten.
- Multiple articles reporting on the same event. Events in larger population centres, or more “newsworthy” events can be covered by multiple news organizations, using different phrasing and sometimes over the course of multiple days. Some events can be reported by the same news organization multiple times over a longer time frame as new information becomes available (and posted as separate articles with separate urls).
All of these types of duplication can result in the same event being included in AONES multiple times. This results in difficulty normalizing the data (i.e., meaningfully representing individual events). Currently, AONES includes steps in the data pipeline to address identical and near-identical duplicates. It does this by comparing the mathematical similarity (using a measure called the Jaccard similarity coefficient) between the first few sentences of the articles. After articles are retained by the vector categorizer step, they are compared to all other retained articles from the previous 24 hours (a moving window is used). If they meet the threshold for similarity, the new article is dropped. This results in only the first appearance of identical or near-identical articles being retained by AONES.
After the list of articles is finalized, data extraction is performed to retrieve the most important and relevant information from the full text of the articles (i.e., data on the drug supply). Consultations with the LDCP’s Knowledge Advisory Group and ODPRN’S LEAG informed the development of the fields for extraction. There are three overarching groups of extracted fields: fields related to the drugs themselves, fields related to the drug supply event, and fields related to the location of the drug event.
The drug fields include:
- the name of the drug (e.g., fentanyl, cocaine, heroin);
- the names of any drugs/contaminants the drug may be mixed with;
- the form (e.g., powder, pill, liquid);
- the appearance – this could include information about the colour, shape, any symbols/words, etc.;
- the quantity – this is typically associated with confiscations and is the amount (generally in weight or number of pills) seized by the police;
- the effect – the physiological outcome of the drug, e.g., overdose, respiratory depression, loss of consciousness, etc.;
- the prevalence – any information available about the frequency of the drug in the drug supply.
The drug event fields include a description of the event itself and any information available about the populations impacted by the event, for example residents of certain regions or demographic sub-populations. The location of the drug event includes any location mentioned in the article.
Large language models (LLM), specifically OpenAI, are used to perform the data extraction. The LLM is given the full text of the article and is prompted to return specific types of information taken only from the provided text. The LLMs also determine relationships between the individual data pieces, for example which quantities are linked to which drugs in a multi-drug confiscation. Rather than having the data returned as free text, as is common in LLMs, an open-source python package called Instructor is used to retrieve structured data (e.g., data in a JSON format) from OpenAI. This allows the data to be used in future data steps. The prompts to OpenAI are designed with descriptions of each of the fields to extract, including examples. Each article can return multiple responses for each field.
As an AI technique, there are limitations to the accuracy of the data extraction. LLMs are trained on large quantities of text. In these training sets, different types of words can be used in a similar context, for example the words handgun and opioid can both occur in descriptions of police confiscations. The content and quality of articles can impact the ability of the model to untangle the relationship between different phrases/concepts, for example in one case the named drug could be fentanyl and it could be mixed with xylazine and in another article the reverse could be true. LLMs can also generate information where it does not exist, colloquially this is called ‘hallucination’. To mitigate this risk, the original url is retained to allow the user to verify the quality of the extraction. The full text of the article is not included in the tool to respect the original media sources.
After the structured extraction, final data processing and cleaning steps are undertaken to prepare the data for the dashboard. This includes re-organizing the data, basic normalization steps of some of the extracted data fields (e.g., dropping the “s” from pills for a consistent form), and masking names of individuals in the extracted information (note: this is a best effort, and some names may still appear). The most significant post-processing step is to resolve the locations returned by OpenAI which can vary from specific street addresses to whole regions. To normalize the data and to ensure that no identifiable location is included in the data, the GIS coordinates returned for the location by OpenAI are sent to ESRI, which returns a structured geographic location. AONES keeps only the city/municipality and country from this geographic location. Only articles from Canada and the United States are retained. Then, as a final step, when the data sent is sent to the dashboard (every 3 hours), it only includes articles from the last 90 days.
For more information about how the data is used and presented within the dashboard, please go the how to use the dashboard page.